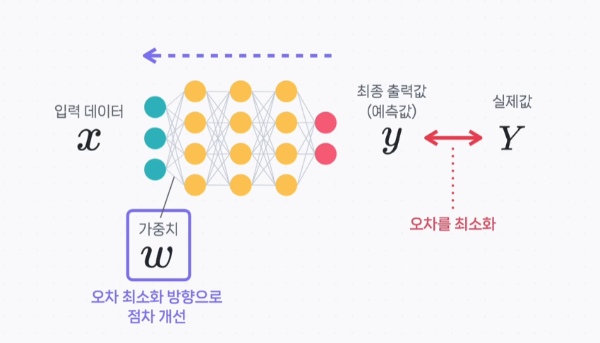
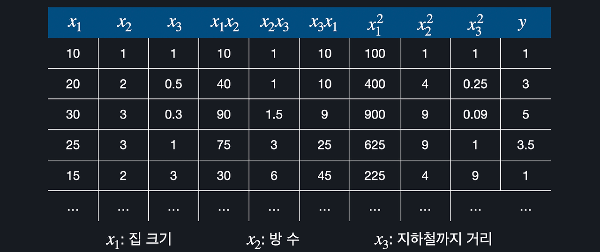
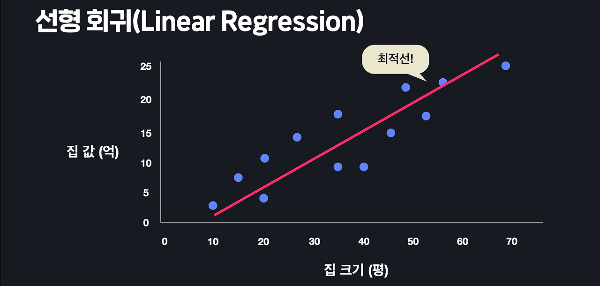
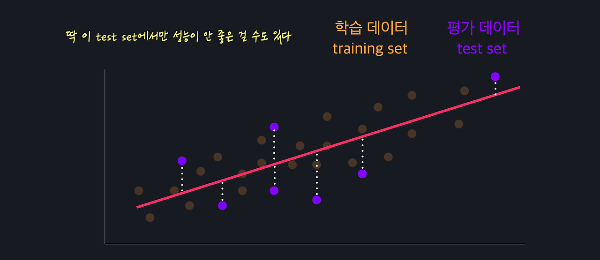
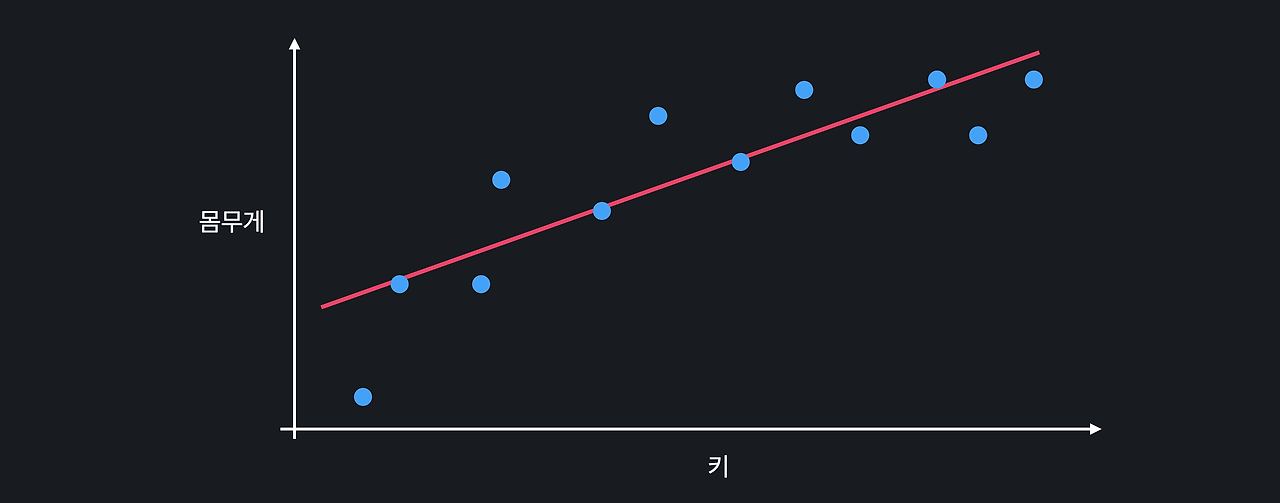
선형 회귀를 통해 하려고 하는 건 학습 데이터에 최대한 잘 맞는 가설 함수를 찾는 것이다. 그러기 위해선 가설 함수를 평가하는 어떤 기준이 있어야 하는데, 그 기준이 되는게 손실 함수이다. 로지스틱 회귀에서도 마찬가지다. 데이터에 잘 맞는 가설 함수를 찾고, 손실 함수를 이용해 가설 함수를 평가한다. 선형 회귀의 손실 함수는 평균 제곱 오차라는 개념을 기반으로 하는데, 데이터 하나하나의 오차를 구한 후에 그 오차들을 모두 제곱항 평균을 내는 작업을 한다. 로지스틱 회귀의 손실 함수는 평균 제곱 오차를 사용하지 않고, 대신 '로그 손실', 영어로는 log loss라는 것을 사용한다. 좀 더 어려운 푷ㄴ으로는 cross entropy라고도 한다. 로그 손실로그 손실은 아래와 같은데, 이를 로그 손실이라고 ..