정규화(Regularization)란?
복잡한 모델을 그대로 학습시키면 과적합이 된다. 이때, '정규화' 라는 기법을 통해 학습 과정에서 모델이 과적합 되는 것을 예방할 수 있다.
아래 좌측 이미지와 같은 학습 데이터를 이용하여 다항 회귀를 해보면 우측 이미지처럼 모델이 과적합되어 복잡한 다항 함수가 나오게 된다.


과적합된 함수는 보통 위아래로 엄청 왔다 갔다 하는 특징이 있다. 많은 굴곡을 이용하여 함수가 training데이터를 최대한 많이 통과하도록 하는 것이다. 함수가 이렇게 급격히 변화한다는 것은 함수의 계수, 즉 가설 함수의 θ값들이 굉장히 크다는 의미이다.
정규화는 모델을 학습시킬 때 θ 값들이 너무 커지는 것을 방지해준다. θ 값들이 너무 커지는 걸 방지하면 아래 이미지처럼 training 데이터에 대한 오차는 조금 커질 수 있어도, 위아래로 변동이 심한 가설 함수를 조금 더 완만하게 만들 수 있다.
이러한 함수는 여러 데이터 셋에 대해 더 일관된 성능을 보이기 때문에 과적합을 막을 수 있는 것이다.
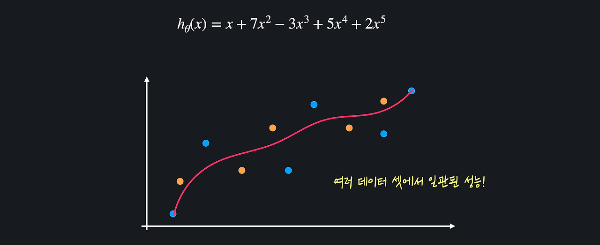
예제
# 라이브러리 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
from math import sqrt
import numpy as np
import pandas as pd
# csv 불러오기
ADMISSION_FILE_PATH = "../data/admission_data.csv"
admission_df = pd.read_csv(ADMISSION_FILE_PATH).drop('Serial No.', axis=1)
# 입력 변수 저장
X = admission_df.drop(['Chance of Admit '], axis=1)
# 6차항 변형기 정의
polynomial_transformer = PolynomialFeatures(6)
# X 데이터에 대해 6차항으로 변형
polynomial_features = polynomial_transformer.fit_transform(X.values)
# 변형된 6차항의 변수 이름들 가져오기
features = polynomial_transformer.get_feature_names_out(X.columns)
# 새로운 DataFrame 생성
X = pd.DataFrame(polynomial_features, columns=features)
y = admission_df[['Chance of Admit ']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=5)
model = LinearRegression()
model.fit(X_train, y_train)
y_train_predict = model.predict(X_train)
y_test_predict = model.predict(X_test)
mas = mean_squared_error(y_train, y_train_predict)
print("training set에서의 성능")
print("-----------------------")
print(sqrt(mas))
mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서의 성능")
print("-----------------------")
print(sqrt(mse))
# 출력값
training set에서의 성능
-----------------------
0.001504818775101219
testing set에서의 성능
-----------------------
5.090675273705169L1, L2 정규화
정규화는 손실 함수에 '정규화 항'이라는 것을 더해서 θ값들이 커지는 것을 방지하는 기법이라고 했다.
아래의 다항 회귀를 예시로 들자면, 데이터에 가장 잘 맞는 선을 찾는 것이 목표인데, 여기서 '데이터에 가장 잘 맞는다'는 것은 데이터에 대한 평균 제곱 오차를 최소화한다는 의미이다.

이때 평균 제곱 오차는 아래와 같이 계산한다.
여기서 계산의 편의를 위해 평균 제곱 오차를 2로 나눠주면 손실 함수 J(θ)가 나온다.

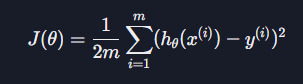
손실 함수는 일반적으로 '가설 함수를 평가하기 위한 함수'이다.
손실 함수의 아웃풋이 작을수록 더 좋은 가설 함수고, 클수록 더 좋지 않은 가설 함수라고 할 수 있는데, 위처럼 다항 회귀는 평균 제곱 오차를 손실 함수로 사용하므로 "training데이터에 대한 평균 제곱 오차가 작을수록 좋은 가설 함수다"란 의미가 된다.

그런데 위 모델은 training데이터에 대한 오차는 굉장히 작으나 test 데이터에 대한 오차는 굉장히 크다. 모델의 θ값들이 너무 커서 training데이터에 과적합이 된 것이기 때문이다. 이와 같은 문제를 해결하기 위해서 좋은 가설 함수의 기준을 'training 데이터에 대한 오차도 작고 θ값들도 작아야 좋은 가설 함수다'로 바꿔줄 수 있다.
이걸 수학적으로 표현해보자면 손실 함수 J는 값이 클수록 가설 함수가 안 좋다는 뜻이기 때문에 아래와 같이 손실 함수에 θ값들의 절댓값, 또는 크기를 더해주면 된다.
단, 여기서 주의해야 할 점은 상수는 과적합과 상관이 없기 때문에 상수의 절대값은 더해주지 않는다.

위 식을 줄이면 아래와 같은 식이 된다.

손실 함수를 이렇게 정의하면 θ값들이 커질수록 손실 함수도 커지고, θ값들이 작아질 수록 손실 함수도 작아지게 된다.
즉, θ값들이 클 수록 좋지 않은 가설이고, θ값들이 작을 수록 좋은 가설 함수라는 의미이다.
예를 들어, 아래와 같은 5차항 함수 2개가 있다고 하면, g의 정규화 항의 값은 10+2+5+3=20, h의 정규화 항의 값은 40+70+50+20=180이 된다. (상수항은 제외!!)

이를 표로 나타내면 아래와 같은 손실 함수 표가 완성 된다.

가설 함수 g는 데이터에 대한 평균 제곱 오차는 h보다 크지만 θ값들이 훨씬 작기 때문에 더 좋은 가설 함수라고 평가하는 것이다.
그런데
사실 정규화 항에는 아래와 같이 λ라는 상수를 곱해준다.

λ는 θ값들이 커지는 것에 대해 얼마나 많은 패널티를 줄 것인지 정한다. 예를 들어 λ가 100이면 θ값들이 조금만 커져도 손실 함수가 굉장히 커지기 때문에 θ값을 줄이는게 중요하고, λ가 0.01이면 θ값들이 커져도 손실 함수는 별로 커지지 않기 때문에 평균 제곱 오차를 줄이는게 중요하다.
이러한 정규화 방식을 L1정규화 라고 하는데 손실 함수에 아래와 같은 정규화 항을 더해 주는 것이다.

그리고 L1 정규화를 사용하는 회귀 모델을 Lasso회귀 모델, 줄여서는 Lasso모델이라고 한다.
L2 정규화도 동일한 개념인데, L2 정규화는 아래와 같은 정규화 항을 더해준다.

θ값의 절대값이 아닌 제곱값을 더해주는 것이다. L1 정규화와 마찬가지로 θ값들이 커지면 손실이 커지기 때문에 θ값들이 커지는 것을 방지해준다. L2정규화를 사용하는 회귀 모델은 Ridge회귀 모델, 또는 Ridge모델이라고 한다.
정규화는 머신 러닝 모델을 학습시킬 때 θ값들이 너무 커지는 것을 방지해주는 기법이다. 손실 함수에 정규화항을 더해 주어서 가설 함수를 평가하는 기준을 바꿔주는 것인데, 아래와 같이 L1 정규화는 아래와 같은 항을 더해 주고,
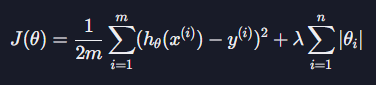
L2 정규화는 아래와 같은 항을 더해 준다.
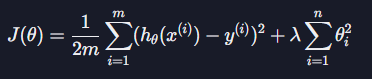
손실 함수를 최소화시키려면 두 항을 모두 줄여야 하기 때문에 데이터에 대한 오차도 작고 θ값들도 작은 가설 함수를 찾을 수 있는 것이다.
데이터에 대한 오차와 θ값 중 어떤 것을 줄이는 게 더 중요한지는 상수 λ에 따라 결정된다. 즉, λ가 클수록 θ값을 줄이는게 중요하고, λ가 작을수록 데이터에 대한 오차를 줄이는게 중요한 것이다.
예제
from sklearn.linear_model import Lasso # Lasso 모델 라이브러리 불러오기
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
from math import sqrt
import numpy as np
import pandas as pd
ADMISSION_FILE_PATH = "../data/admission_data.csv"
admission_df = pd.read_csv(ADMISSION_FILE_PATH).drop('Serial No.', axis=1)
# 입력 변수 저장
X = admission_df.drop(['Chance of Admit '], axis=1)
# 6차항 변형기 정의
polynomial_transformer = PolynomialFeatures(6)
# X 데이터에 대해 6차항으로 변형
polynomial_features = polynomial_transformer.fit_transform(X.values)
# 변형된 6차항의 변수 이름들 가져오기
features = polynomial_transformer.get_feature_names_out(X.columns)
# 새로운 DataFrame 생성
X = pd.DataFrame(polynomial_features, columns=features)
y = admission_df[['Chance of Admit ']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=5)
model = Lasso(alpha=0.001, max_iter=1000) # 람다를 alpha값으로 지정, Lasso는 손실 함수를 최소화 하기 위해 경사하강법을 사용하므로 경사 하강의 횟수를 지정할 수 있음
# L2정규화를 사용하고 싶다면
# model = Ridge()
# 파라미터는 L1과 동일
model.fit(X_train, y_train)
y_train_predict = model.predict(X_train)
y_test_predict = model.predict(X_test)
# 평균 제곱근 오차를 이용하여 모델의 성능을 평가
mas = mean_squared_error(y_train, y_train_predict)
print("training set에서의 성능")
print("-----------------------")
print(sqrt(mas))
mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서의 성능")
print("-----------------------")
print(sqrt(mse))
# 출력값
training set에서의 성능
-----------------------
0.05389371888907575
testing set에서의 성능
-----------------------
0.06689735278061709L1 정규화 실습 (*L2는 model을 Ridge로만 변경하면 됨)
from sklearn.linear_model import Lasso # Lasso -> Ridge로 변경 가능
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
from math import sqrt
import numpy as np
import pandas as pd
# 데이터 파일 경로 정의
INSURANCE_FILE_PATH = './datasets/insurance.csv'
insurance_df = pd.read_csv(INSURANCE_FILE_PATH) # 데이터를 pandas dataframe으로 갖고 온다 (insurance_df.head()를 사용해서 데이터를 한 번 살펴보세요!)
insurance_df = pd.get_dummies(data=insurance_df, columns=['sex', 'smoker', 'region']) # 필요한 열들에 One-hot Encoding을 해준다
# 입력 변수 데이터를 따로 새로운 dataframe에 저장
X = insurance_df.drop(['charges'], axis=1)
polynomial_transformer = PolynomialFeatures(4) # 4 차항 변형기를 정의
polynomial_features = polynomial_transformer.fit_transform(X.values) # 4차 항 변수로 변환
features = polynomial_transformer.get_feature_names_out(X.columns) # 새로운 변수 이름들 생성
X = pd.DataFrame(polynomial_features, columns=features) # 다항 입력 변수를 dataframe으로 만들어 준다
y = insurance_df[['charges']] # 목표 변수 정의
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=5)
model = Lasso(alpha=1, max_iter=2000, normalize=True) # Lasso -> Ridge로 변경 가능, normalize는 버전별 상이하므로 빼도 됨
model.fit(X_train, y_train)
y_test_predict = model.predict(X_test)
y_train_predict = model.predict(X_train)
mse = mean_squared_error(y_train, y_train_predict)
print("training set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')

위 결과를 통해 4차 항의 높은 회귀 모델을 사용해도 성능이 training과 test 셋에서 큰 차이가 없는걸 확인할 수 있다.
LogisticRegression
정규화는 모델의 파라미터 (즉 학습을 통해 찾고자 하는 값들 - 회귀의 경우 θ)에 대한 손실 함수를 최소화 하는 모든 알고리즘에 적용할 수 있다. 따라서 다중 회귀, (다중) 다항 회귀, 로지스틱 회귀 모델 모두에 정규화를 적용할 수 있는데 모델에 해당하는 손실 함수에 아래의 정규화 항을 더해주면 된다.
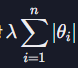

scikit-learn같은 라이브러리를 사용해서 실제로 모델을 만들 때는 알아서 정규화를 적용해 주는 모델을 사용하면 되는데 다중 회귀 또는 다항 회귀 모델을 만들 때는 LinearRegression 대신 Lasso (L1 정규화) 또는 Ridge (L2 정규화) 모델을 사용하면 된다.
그러면 로지스틱 회귀 모델을 구현한 LogisticRegression에 정규화를 적용하고 싶으면 어떻게 해야 할까?
LogisticRegression 모델은 사실 자동으로 L2 정규화를 적용합니다. 그래서 정규화를 적용하도록 따로 모델을 바꿔주지 않아도 된다. 어떤 정규화 기법을 사용할지는 모델의 penalty 라는 옵셔널 파라미터로 정해 줄 수 있다.
LogisticRegression(penalty='none') # 정규화 사용 안함
LogisticRegression(penalty='l1') # L1 정규화 사용
LogisticRegression(penalty='l2') # L2 정규화 사용
LogisticRegression() # 위와 똑같음: L2 정규화 사용L1과 L2 정규화의 차이점
- L1 정규화는 여러 θ값들을 0으로 만들어 줍니다. 모델에 중요하지 않다고 생각되는 속성들을 아예 없애준다.
- L2 정규화는 θ값들을 0으로 만들기보다는 조금씩 줄여 준다. 모델에 사용되는 속성들을 L1처럼 없애지는 않는다.
