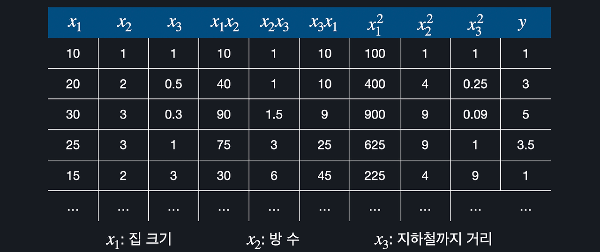
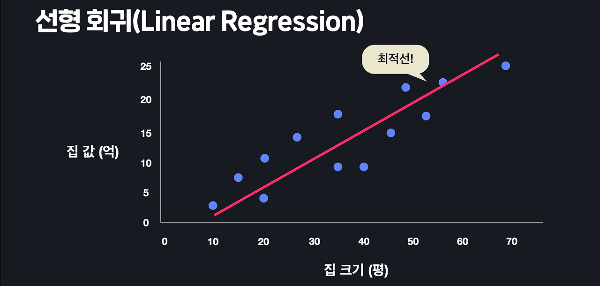
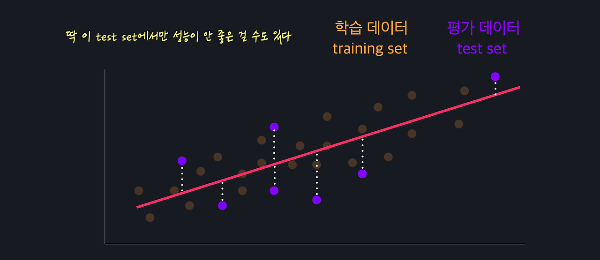
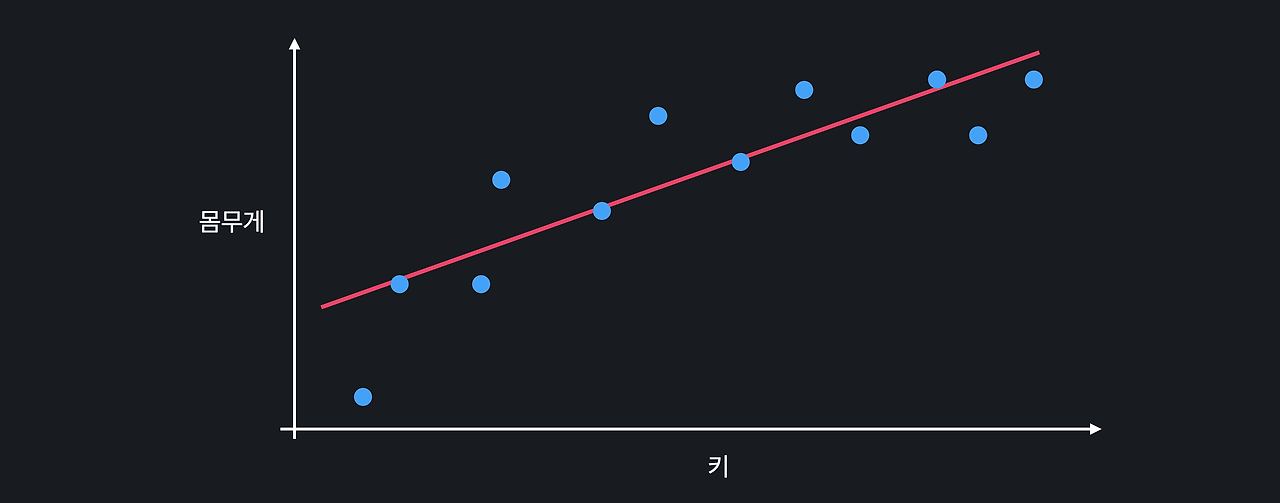
'금융' 관련 머신러닝 사례를 찾아보다가 ChatGPT로 주식 가격과 코인 가격을 예측해 본 아티클을 발견했다. 찬찬히 읽어보았는데,시도해보면 재미있을 것 같아서 테슬라로 간단히 시도해보았다. 우선, 내가 참고한 아티클은 카카오뱅크 기술기획팀 William에서 발행한 글인데, ChatGPT를 뉴스 분석에 활용하여 주가를 예측하는 방법의 효과성을 검증한 논문을 소개한다. 사실 더 흥미로운 건, 이 다음 아티클에서 “카카오뱅크에서 ChatGPT를 이용한 암호화폐의 가격 예측에 관해 연구한 내용“을 소개하는데, 논문까지 있어서 한번 읽어보기 좋다. 카카오뱅크, 'CahtGPT로 주식 가격 예측하기' ChatGPT로 주식 가격 예측하기OpenAI의 ChatGPT가 금융시장 분석에 미치는 영향을 연구한 최..