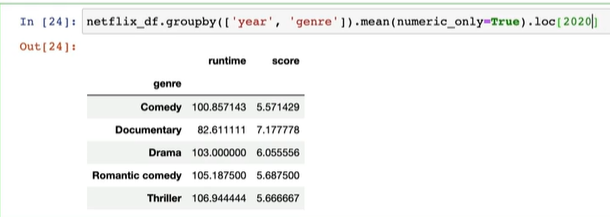
groupby()netflix_df.groupby('genre').count()# 컬럼별로 결측값을 제외한 각 데이터가 몇개씩 있는지 알 수 있음netflix_df.groupby('genre').size()# genre컬럼을 기준으로 그룹화# .size(): 각 장르별로 로우가 몇개인지 한 줄의 시리즈로 표현됨(*결측값 포함)netflix_df.groupby('genre').min(numeric_only=True)# min에 문자데이터가 적용될 경우, 문자 데이터의 최소값은 오름차순을 했을 때 가장 첫번째 값# 숫자 데이터만 요약해서 보고 싶다면 'numeric_only=True'를 설정해줘야 함# min 외 max, mean, sum 모두 사용법 동일함netflix_df.groupby('genre')[..