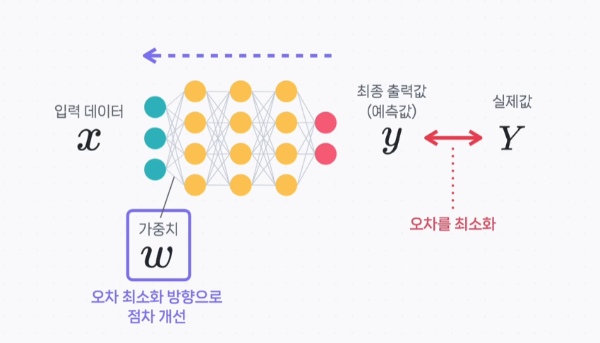
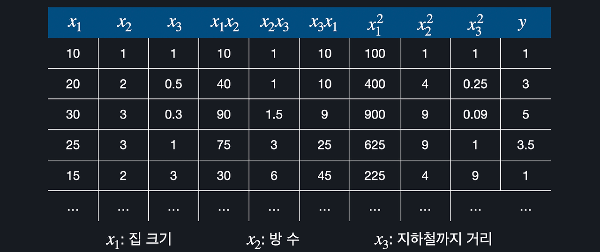
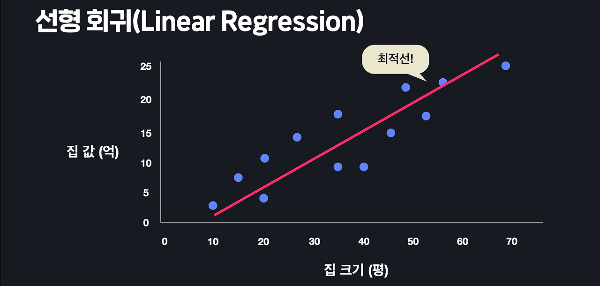
최적화가 어려운 이유1. 모델의 비선형성2. 고차원성과 과적합3. 그래디언트 소실 문제4. 하이퍼파라미터의 민감성하이퍼파라미터란?하이퍼파라미터란, 모델의 학습 과정에서 사용자가 사전에 설정해야 하는 값으로 모델의 성능 최적화를 위해 중요한 역할을 한다. 주로 딥러닝 학습 전에 설정되며, 학습 과정을 제어하는데 사용된다.모델의 학습 속도, 안정성, 최종 성능에 직접적인 영향을 미치며 적절한 하이퍼파라미터의 설정은 과적합 방지, 학습 효율, 모델 성능 최적화에 중요한 열할을 한다. 하이퍼파라미터의 종류1. 배치 크기(Batch Size)한 번의 학습 단계에 사용되는 데이터 샘플의 수이다. 이는 모델이 학습하는 데이터의 양을 결정해서 메모리 사용량과 학습 속도에 큰 영향을 미친다. 배치 크기가 작으면, 메모리..