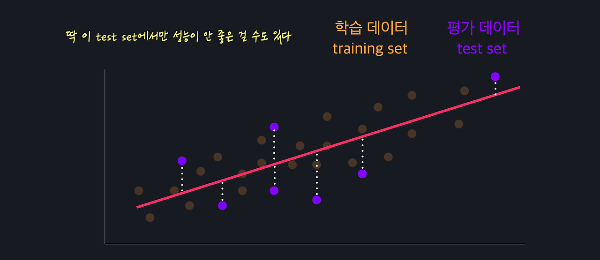
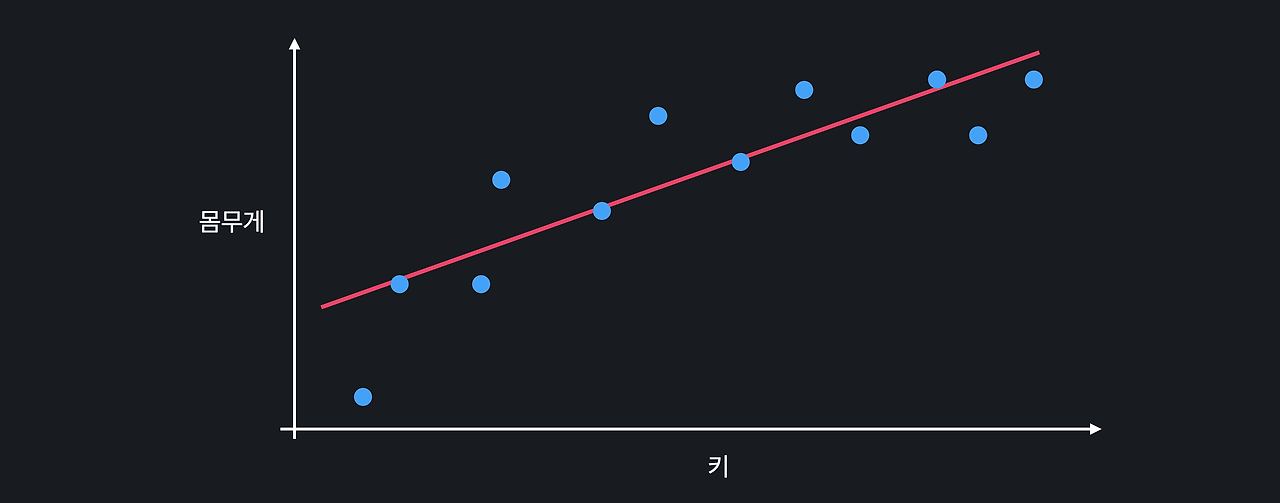
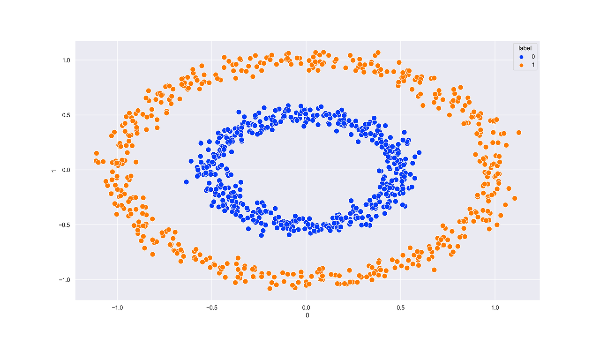
하이퍼 파라미터 (Hyperparameter)많은 머신 러닝 알고리즘은 학습을 하기 전에 미리 정해주어야 하는 변수 또는 파라미터들이 있다.여기서 하이퍼 파라미터란 학습을 하기 전에 미리 정해줘야 하는 변수 또는 파라미터들을 의미하는데 scikit-learn에서 보통 모델을 만들 때 옵셔널 파라미터로 정해주는 변수들이다.하이퍼 파라미터에 어떤 값을 넣어주느냐에 따라 성능에 큰 차이가 있을 수 있기 때문에 모델의 성능을 높여주는 좋은 하이퍼 파라미터를 고르는게 굉장히 중요하다. 예를 들면, Lasso는 L1 정규화를 해주는 회귀 모델인데, scikit-learn에서 Lasso 모델을 만들 때 alpha와 max_iter라는 옵셔널 파라미터를 지정해 준다. model = Lasso(alpha=0.001, ..