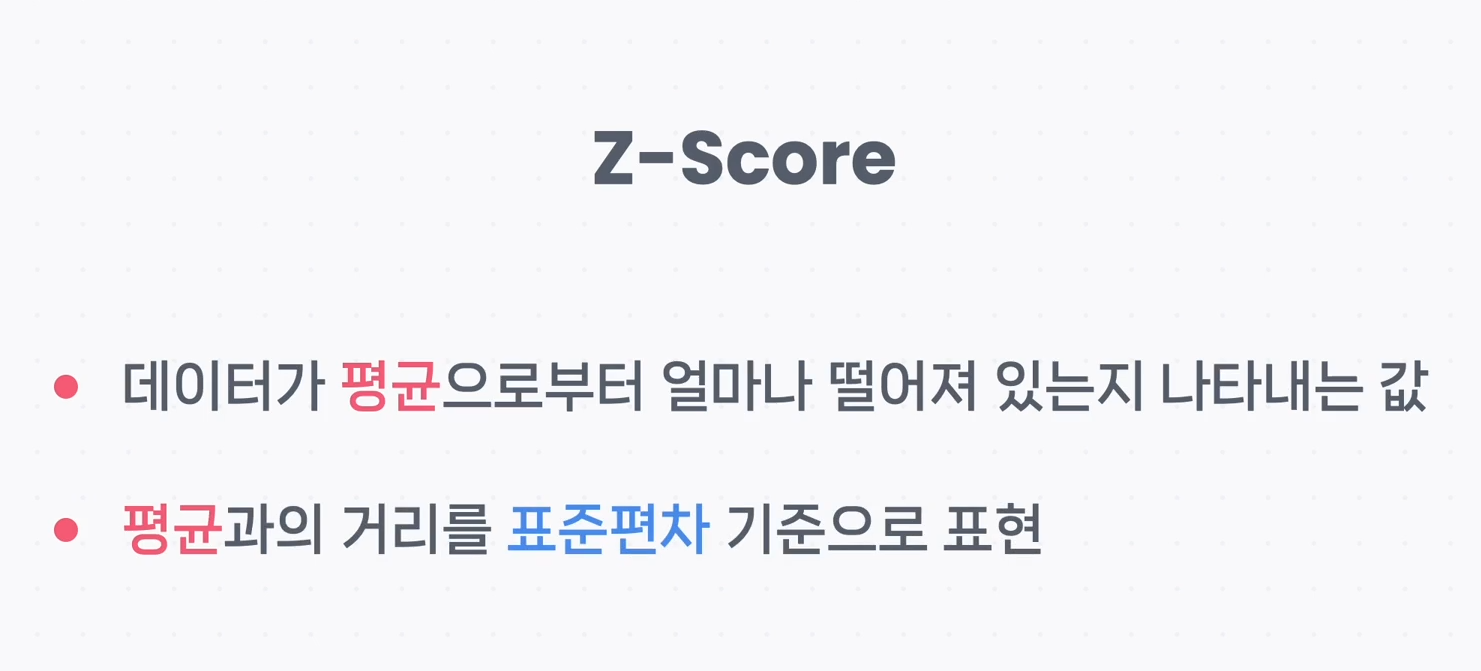
스케일링정규화(Normalization)예제)import pandas as pdpatient_df = pd.read_csv('data/patient.csv')w_min = patient_df['weight'].min()w_max = patient_df['weight'].max()patient_df['weight'] = ((patient_df['weight'] - w_min) / (w_max - w_min))patient_df#######################import pandas as pdpatient_df = pd.read_csv('data/patient.csv')patient_df['weight'] = (patient_df['weight'] - patient_df['weight'].min()..