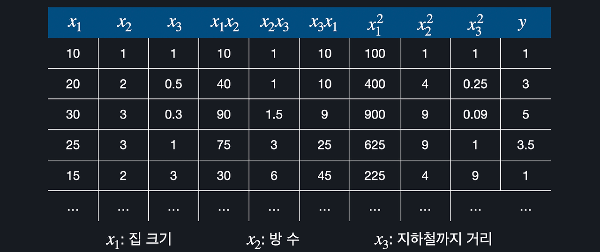
다항회귀란?선형 회귀는 학습 데이터에 가장 잘 맞는 일차식을 찾아서 예측을 하는 알고리즘인 반면, 다항 회귀는 고차식을 찾아서 예측하는 알고리즘이다. 집 값 예측 문제를 생각해보자. 항상 집의 크기라는 변수가 주어진다는 가정을 했고 이걸 하나의 속성으로 이용했는데 사용하는 데이터가 항상 이렇게 하나만 사용해도 의미가 있는 완벽한 변수일 수는 없다. 예를 들어 집이 사각형이라고 가정하고 집 크기 대신 집의 높이와 너비 데이터만 있다고 하자.사실 아무리 너비가 커도 높이가 작거나, 높이만 크고 너비만 작으면 크기가 작고 구조가 효율적이지 않기 때문에 집 값이 높지 않다. 사실 이 두 변수들보다 집값을 예측하는 데 훨씬 좋은 수치는 이 둘을 곱한 값, 집의 넓이다.단순 선형 회귀를 사용하면 이 두 변수가 서..