Convolution Layer란?
Convolution 연산이 수행되는 네트워크 레이어로, Convolution 연산은 결국 지역적 특성을 추출하는 과정이라고 볼 수 있다.

Convolution 연산 방법
Convoltion 연산은 어떻게 하는걸까?
간단히 말하자면 입력 데이터에 Kernel이라고 불리는 필터를 적용해서 값을 계산하는 과정이다.
필터는 카메라의 렌즈와 비슷한 역할을 하는데, 카메라 필터는 렌즈앞에 씌워서 센서에 맺히는 상에 변화를 주는 역할로 어떤 입력이 필터를 통과하면 변형을 가하여 조금 바뀐 결과물이 나오는 것이다.

그럼 Convolution Filter는 어떤 계산을 하는걸까?
Convolution Filter는 이미지 사이즈보다 작은 크기의 행렬이다. 아래 이미지에선 가로 3칸, 세로 3칸으로 3x3크기로 되어 있는데 Convolution 연산을 위해서 이 작은 조각을 입력 데이터의 좌측 상단에 대응시키는 것부터 시작하게 된다.

입력 데이터의 숫자와 필터에 있는 값을 같은 위치끼리 하나씩 곱하여 이 값들을 모두 더한다. 이렇게 곱한 값들을 다 더한다고 하여 Convolution 연산을 합성곱이라고 부르기도 하고, 기호는 *(별표)로 자주 표기된다.
위에서 Convolution 연산의 기본적인 원소별 곱의 합 과정을 볼 수 있었다.
하지만 실제로 CNN에서 Convolution Layer를 사용할 때에는 입력과 출력의 채널 수를 고려해야 한다.
입력 Layer의 RGB 이미지처럼 입력 채널이 3개라고 하면, Kernel의 채널도 3개가 된다. 따라서 Convolution 연산의 최종 결과는 채널별로 구한 값을 다시 모두 더하여 계산하게 된다.
또한 Kernel 하나에는 최종적으로 더해지는 Bias값도 같이 학습된다.
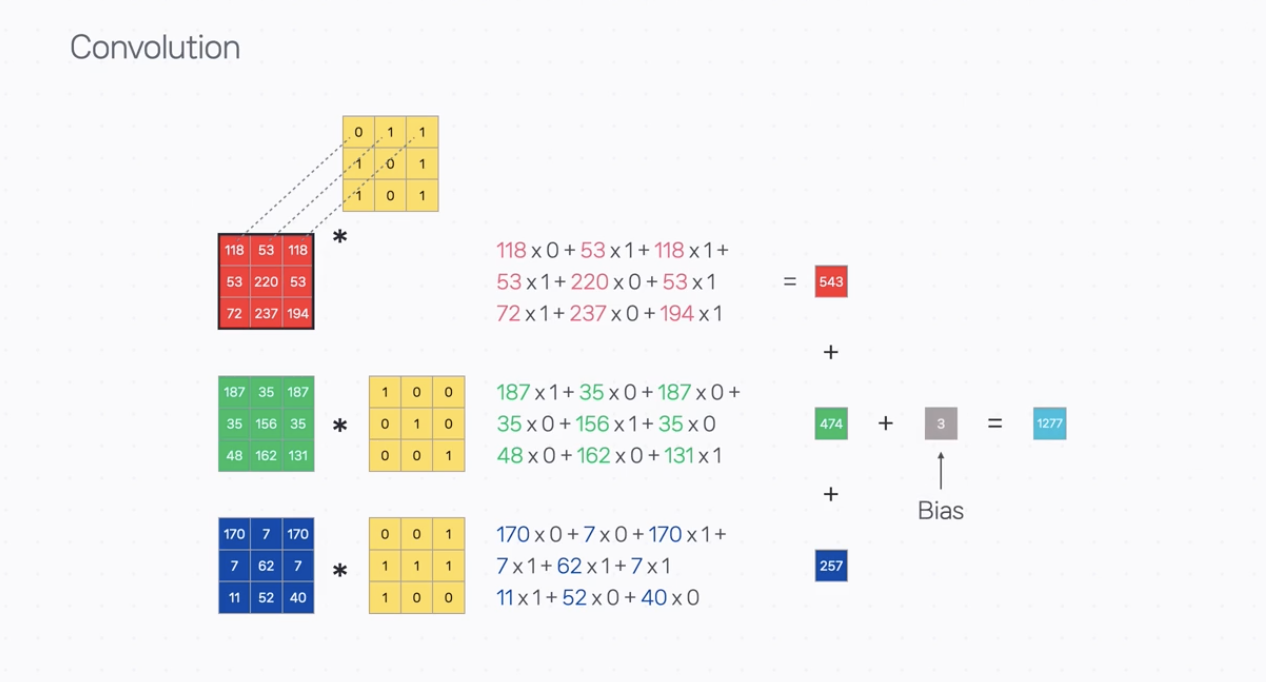
이렇게 한번의 계산이 끝나면 한간씩 필터를 옮겨가면서 모두 계산을 하는데, 이걸 Feature Map(특성 맵)이라고 한다.
Feature Map(특성 맵)

Feature Map은 실제로 이미지라기 보단 입력의 각 픽셀에 대응되는 특징을 위치 정보를 유지한 순서대로 출력한 것이다.

위의 예시에서 Feature Map(특성 맵)의 첫 번째 값은 입력의 (1, 1) 주변 3x3 영역에서의 지역적인 특성을 수치화 한 것이 되고, 그 다음 값은 (1, 2) 주변 3x3 영역에서의 지역적 특성 값이 되는 것이다.
그리고 여기 Kernel에 있는 값들은 고정된 값이 아닌, 추후 모델이 데이터를 통해 학습하는 파라미터이며, 이미지의 특징을 가장 잘 파악할 수 있는 방향으로 바뀌게 된다.

이러한 Convolution Filter의 크기를 바꿀 수도 있는데 이를 커널 크기(Kernel Size)라고 부른다.
Kernel Size

좀 더 넓은 주변부의 정보를 요약하고 싶다면 Kernel의 크기가 커지면 된다.

그리고 지금까지는 Kernel이 한 칸씩 이동했는데 Filter를 몇 칸씩 이동할 지 설정할 수도 있다. 이를 Stride라고 부른다.
Stride
stride의 기본값은 1이며, stride가 2일 경우 Filter가 두 칸씩 이동하게 된다.

즉 한 칸씩 건너뛰어 계산하게 되므로 출력되는 Feature Map의 크기가 줄어드는 것을 확인할 수 있다.
Stride를 하는 이유는 Convolution 연산의 연산량이 많기 때문에 연산 복잡도를 줄일 필요가 있기 때문이다.

Convolution 연산은 Kernel 크기만큼의 주변 정보를 모아서 하나의 출력 픽셀로 전달하는 역할을 한다. 따라서 Stride가 2인 경우에 한 칸 건너 뛰어도 아예 정보전달이 되지 않은 입력값은 없는 것이다. 이처럼 Convolution 연산의 계산량을 조금 줄일 수 있고, 어느 정도 효율적으로 이미지의 특징을 추출할 수 있게 된다.
그런데 Convolution 연산을 하면 출력되는 Feature Map이 원래 입력 이미지보다 작아지게 된다.

이를 해결하기 위해 Padding 방법을 사용한다.
Padding
왼쪽 끝에 있는 부분은 Filter를 한 번 거치고 나면 그다음에는 연산에 포함되지 않는다. 딱 한 번만 사용되는 것이다.
반면, 오른쪽 상단 중간부에 있는 부분은 총 3번 반영된다. 두번째 픽셀은 총 2번 반영되고, 가장 가운데 있는 부분은 총 9번 반영된다.
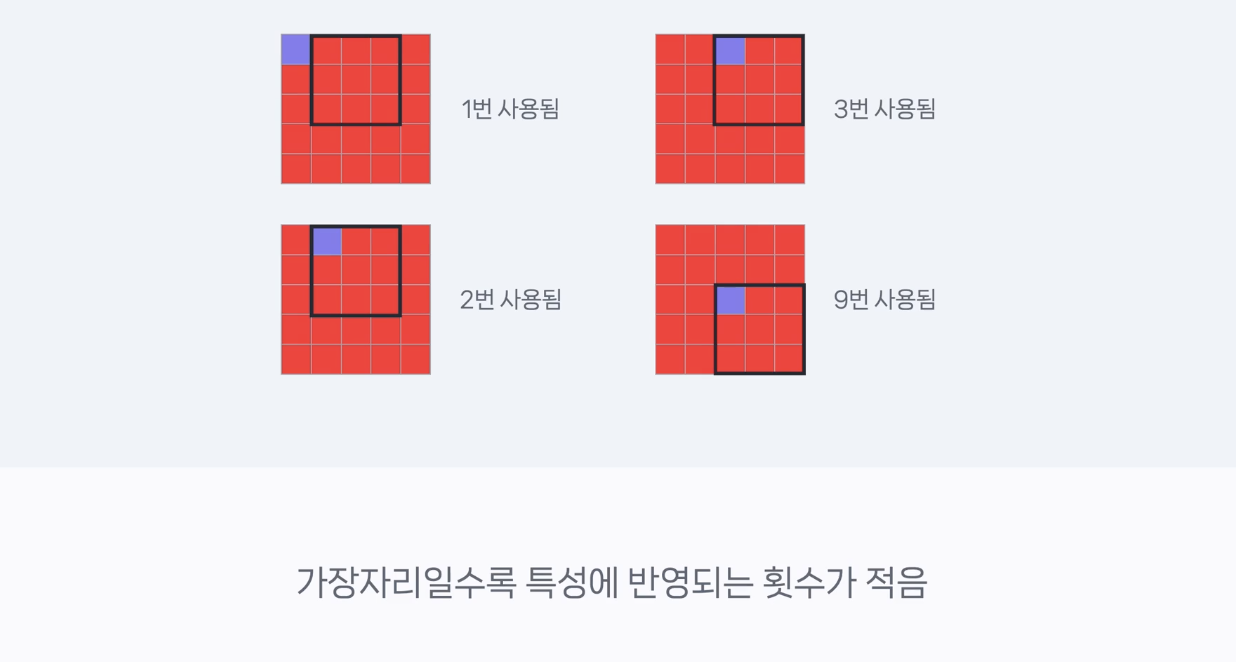
이처럼 이미지 가운데보다 가장자리 정보는 상대적으로 덜 반영될 수 밖에 없다.
1) Feature Map이 원래 입력 이미지보다 작아지는 문제와 2) 특성에 반영되는 횟수 불균형의 문제를 해결하기 위해 이미지 가장자리에 임의의 값들을 채워 넣는 Padding 이라는 방법을 사용한다.

보통은 0으로 채워주는 경우가 많은데, 가장자리에 Padding을 해주면 입력 이미지의 크기 자체가 커지는 효과가 있다.
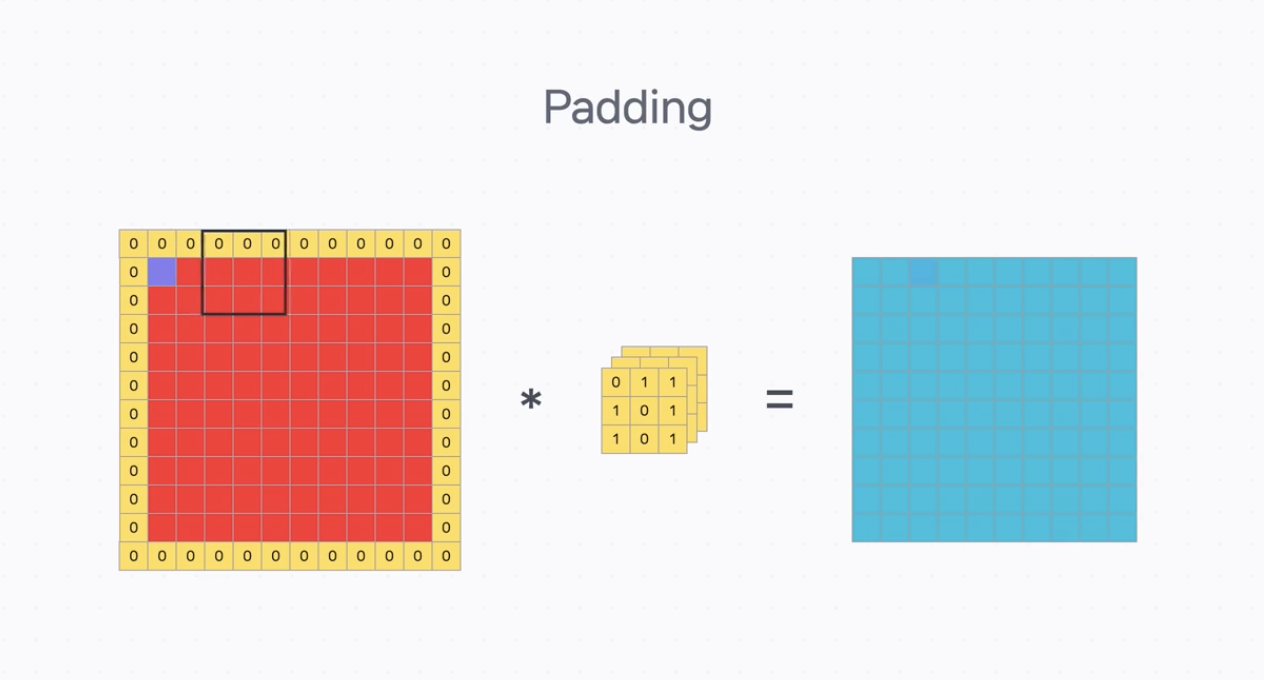
그래서 Convolution 연산을 한 후에도 결과로 나온 Feature Map의 크기가 원래의 입력 이미지 사이즈와 동일하게 되는 것이다.
그리고 이미지 가장자리의 정보도 더 잘 반영된 결과물을 얻을 수 있다. 가장자리 모서리는 한 번 반영되던 것이 네 번으로 늘어나서 전체적으로 각 부분이 골고루 Feature Map에 반영되게 된다.
원래는 위치별로 1~9번 사이로 사용되었지만, Padding을 한 이후에는 각 위치에 있는 값들이 4~9번 사이로 사용되게 된 것이다.

그렇다면 시각적 이미지의 지역적 특성을 추출하는 Convolutional Layer는 어떻게 구성될까?
Convolution Layer 구성
위에서 외곽선 정보, 색상 조합, 질감, 패턴 등 여러가지 시각적 특성을 추출할 수 있다고 했는데, 여러 특성을 학습하기 위해서는 여러개의 대응되는 kernel들이 필요하다.
Kernel을 한 번 적용하면 Feature Map이 하나 생기게 된다. 즉, 입력 이미지는 Kernel 수 만큼의 Feature Map으로 변환된다.

이 한묶음의 Feature Map을 추출하는 n개의 Kernel이 Convolutional Layer 하나를 구성하는 요소가 된다.