CNN이란?
강아지와 고양이를 구분하는 딥러닝을 만든다고 할 때,
이미지 데이터를 컴퓨터가 인식할 수 있는 형태로 표현하게 되는데 기본적으로 비트맵이란 형식으로 나타내게 된다.
비트맵은 가로x세로 크기가 있는 영역에 픽셀이라고 부르는 점을 찍어서 그림을 표현하는 방식이다.
각 픽셀은 픽셀값이라고 부르는 빛의 강도를 가지고 있다.
아래 숫자 1 이미지는 글씨 영역에 해당하는 윗 부분은 검은색으로 되어 있고 아래로 갈 수록 점점 밝은 회색으로 되어 있다.
흰색이 빛의 강도가 가장 강한 것으로 255, 검은색이 0으로 표현된다.

그렇다면
컬러 이미지는 어떻게 표현할까?
빛의 삼원색인 빨강, 초록, 파랑을 각각 나눠서 표현하게 되는데 채널이라고 부르는 동일한 크기의 영역 각각에
마찬가지로 빨강, 초록, 파랑 빛의 강도를 0에서 255사이로 표현하게 된다.
따라서 이런 이미지 데이터의 크기는 가로X세로X채널 수 로 구할 수 있다.
이걸 일반적인 Fully Connected Network로 학습하도록 만든다면 어떨까?
데이터를 일자로 쭉 펴서 픽셀 하나하나의 값을 가지고 학습을 전부 해야 한다.
가로, 세로 픽셀이 각각 10x10인 컬러 이미지의 경우, 300픽셀이 그대로 300차원의 벡터 x가 된다.
하지만 이런 방법은 이미지가 조금만 복잡해져도 좋은 성능을 내기 어렵다.
이는 모델 구조가 이미지의 지역적 특성을 제대로 파악하지 못하기 때문인데,
이미지의 지역적 특성이란 이미지 내에서 객체나 형태와 같은 특징이 부분적으로 나타나는 것을 의미한다.
예를 들어, 고양이 이미지에서 눈이나 코, 귀와 같은 부분처럼 특정 영역에 이미지의 형상에 관한 정보가 각각 존재한다.
이러한 지역적인 특성을 잘 파악하는 것이 이미지를 인식하고 이해하는데 중요하다.
그런데 이미지는 작은 지역의 형태적 특징이 모여 큰 형태를 만들고 2차원 구조를 만들게 된다.
이것을 Fully Connected Network로 인식한다는 것은 각 부분을 인식하는 가중치인 Weight를 모두 따로 따로 인식한다는 말이다.
예를 들어, Fully Connected Network 에서 첫 번째 뉴런이 외곽선 정보를 담당하는 뉴런이라고 해보자.
그럼 이 뉴런은 이미지의 첫 번째 (1, 1, 1) 픽셀로부터의 가중치, 두 번째 (1, 1, 2) 픽셀로부터의 가중치, 세 번째 (1, 1, 2) 픽셀로부터의 가중치 이후로 모든 각 픽셀로부터의 가중치를 모두 학습해야 한다.
인식해야하는 특성에 비해 학습시켜야 하는 가중치가 과도하게 많아서 학습이 잘 되지 않고 비효율적이게 되는 것이다.
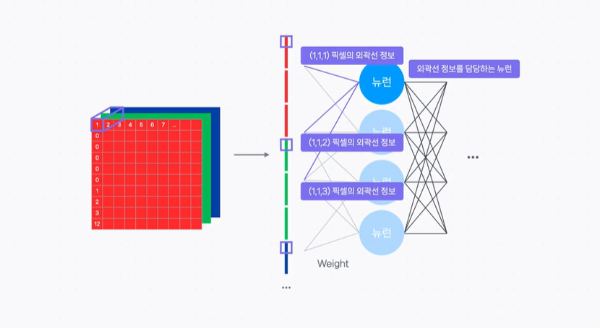
위의 이미지는 첫 번째 픽셀에 대해 외곽선이라는 특성을 인식할 수 있는 뉴런이다.
Fully Connected Network의 연결을 생각해보면 결국 입력 이미지의 위치별로 외곽선 특성을 인식하는 뉴런이 각각 필요하다는 것을 알 수 있다.
외곽선이라는 특성 외에도 질감이나 다른 이미지의 지역적인 특성을 인식할 수 있는 가중치를 모두 학습시켜야 한다.
그러면 결국 모든 픽셀마다 이런저런 특성을 추출하는 뉴런이 필요하게 된다.
그런데 잘 생각해보면
어떠한 이미지의 보편적인 특징이 이미지의 상대적인 위치마다 모두 다르진 않다.
따라서 위치별 특징을 잡는 뉴런은 중복이 된다고 볼 수 있다.
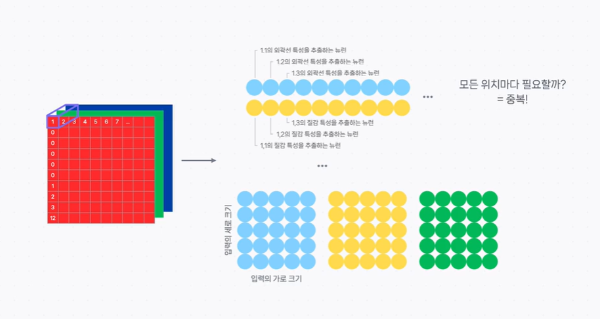
이러한 비효율을 개선하기 위해서 '지역적인 특성을 추출할 수 있는 적당히 작은 고정된 크기의 단위로 묶어서 학습하자' 라는 방안이 CNN의 시작이라고 볼 수있다.
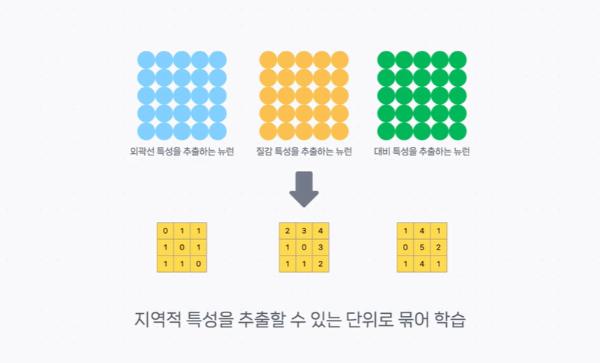
이렇게 묶인 지역적 특성을 추출할 수 있는 학습 파라미터를 Convolution Filter라고 한다.
Convolution Filter

Convolution Filter는 Kernel이라고도 부르는데, 이미지 크기보다 작은 크기의 행렬이고, 각각의 행렬값이 딥러닝의 학습 파라미터인 Weight라고 할 수 있다.
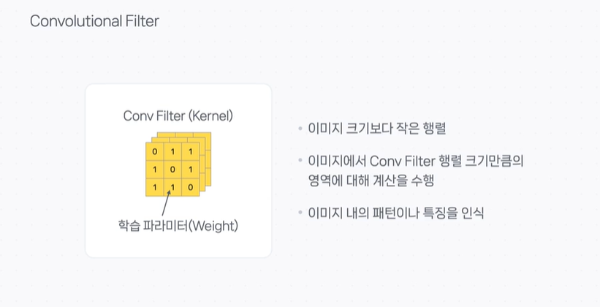
Convolution 연산을 통해 단순히 픽셀값 하나하나 혹은 전체 이미지를 한 번에 인식하는 것이 아니라 Filter크기만큼의 부분적인 영역에 대한 계산을 수행해서 형태나 질감같은 중요한 지역적 정보를 인식하는 Weight를 효과적으로 학습하게 된다.
Convolution Filter를 이용한 연산을 'Convolution 연산'이라 부르고 이런 Convolution 연산을 포함한 Convolutional Layer로 이루어진 네트워크 구조를 Convolutional Neural Network, 줄여서 CNN이라고 부른다.
그러면 CNN을 어떤 분야에서 많이 사용하게 될까?
Computer Vision이라고 부르는 여러 작업들을 수행하게 되는데, 대표적인 기본 세 가지 태스크를 알아보자.
Computer Vision Tasks

Image Classification
주어진 이미지가 어느 카테고리에 속하는지 분류하는 문제다.
예를 들어, 강아지와 고양이 외에도 사람, 자동차 등의 사물에 대한 클래스가 정해져 있어 어떤 클래스인지 맞추는 문제다.
Object Detection
주어진 이미지에서 특정 카테고리에 속하는 물체가 어디에 등장하는지 탐지하는 문제다. 사진에서 얼룩말이 어디에 등장하는지 빨간 형태로 찾고 있다.
Image Segmentation
주어진 이미지에서 각 부분(픽셀)이 어떤 카테고리에 속하는지 분류하는 문제다. 사진의 노란색으로 색칠한 픽셀이 사람을 나타내고, 파란색으로 색칠한 픽셀은 자동차를 나타낸다.
그렇다면 CNN 모델은 어떠한 식으로 구성되어 있을까?
CNN 모델 구조
대부분의 딥러닝 모델은 입력층, 은닉층, 출력층 즉, Input Layer, Hidden Layer, Output Layer 구조를 가진다고 볼 수 있다.
여기서 Hidden Layer를 어떻게 구성하는지에 따라서 모델의 특징과 성능이 달라지게 된다.
지금까지 배운 딥러닝 모델에서는 Fully Connected Network 위주로 사용했다.
CNN에서는 Hidden Layer쪽에 Convolutional Layer와 Pooling Layer 라는 레이어가 사용된다.
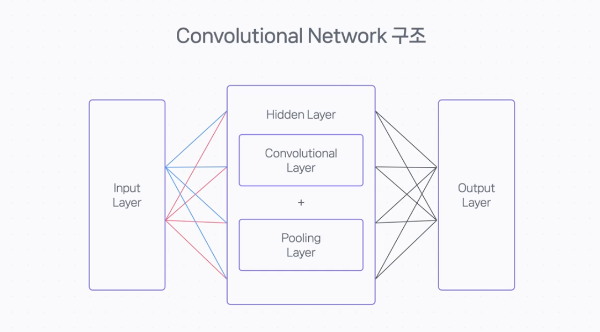
CNN이라고 해서 특별한 무언가가 있는 것은 아니며 이런 종류의 Layer들을 사용해서 Network가 구성되어 있고, 학습 또한 역전파를 통해 이루어진다고 보면 된다.