groupby()
netflix_df.groupby('genre').count()
# 컬럼별로 결측값을 제외한 각 데이터가 몇개씩 있는지 알 수 있음netflix_df.groupby('genre').size()
# genre컬럼을 기준으로 그룹화
# .size(): 각 장르별로 로우가 몇개인지 한 줄의 시리즈로 표현됨(*결측값 포함)netflix_df.groupby('genre').min(numeric_only=True)
# min에 문자데이터가 적용될 경우, 문자 데이터의 최소값은 오름차순을 했을 때 가장 첫번째 값
# 숫자 데이터만 요약해서 보고 싶다면 'numeric_only=True'를 설정해줘야 함
# min 외 max, mean, sum 모두 사용법 동일함netflix_df.groupby('genre')['score'].meat()
# groupby 한 조건에서 특정 컬럼만 보고 싶다면 [' ']에 넣어줌(*리스트 가능)예제
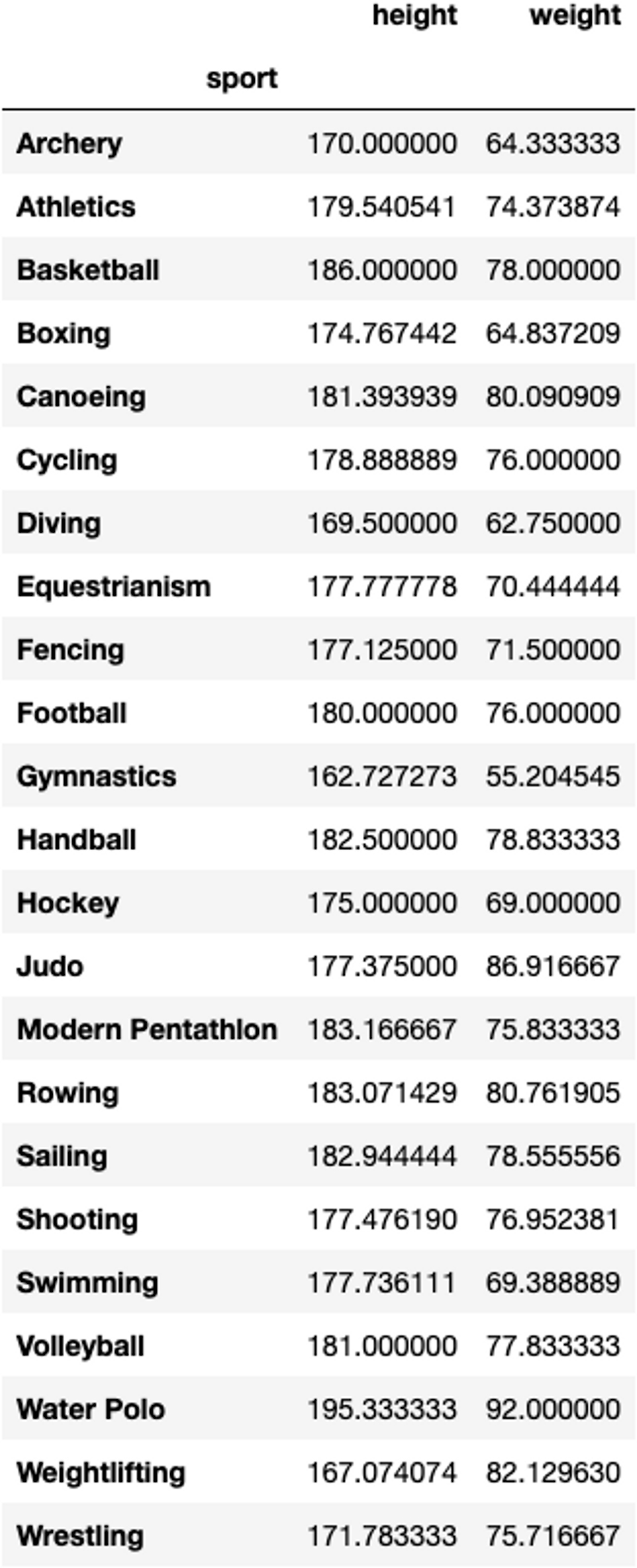
우리나라가 최초로 금메달을 획득한 1976년 몬트리올 올림픽의 메달리스트 데이터를 분석해 봅시다. Groupby를 사용해서 아래와 같이 각 종목별로 메달리스트들의 평균 키와 체중을 계산해 주세요. 참고로 단체 종목은 출전한 선수들 중 1명의 정보만 저장되어 있습니다.
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
olympic_df.groupby('sport')[['height', 'weight']].mean()결과값
Categorical()
- 목적: 데이터를 정렬할 때, groupby를 할 때도, 그래프를 그릴 때도 그냥 가나다 순이나 abc 순이 아니라 원하는 대로 순서를 매겨서 볼 수 있다.
- 사용법: pandas의 Categorical()이라는 함수 안에 category 타입으로 바꿀 데이터를 넣고, ordered라는 파라미터 값을 True로 설정하면 된다. (*ordered 파라미터의 디폴트 값은 False이기 때문에, 범주별 순서를 매기려면 이 값을 따로 True로 설정해 주어야 함) 그리고 categories라는 파라미터에 리스트를 활용해서 각 범주 값을 원하는 순서대로 넣어 주면 된다. 예를 들어 아래 코드처럼 ['XS', 'S', 'M', 'L', 'XL']을 넘겨주면 사이즈가 XS-S-M-L-XL 순으로 순서가 매겨진다.
pd.Categorical(clothes_df['size'], ordered=True, categories=['XS', 'S', 'M', 'L', 'XL'])
# 출력값
['L', 'S', 'XS', 'L', 'S', ..., 'XS', 'M', 'S', 'L', 'XL']
Length: 20
Categories (5, object): ['XS' < 'S' < 'M' < 'L' < 'XL']
# size 컬럼에 다시 지정
clothes_df['size'] = pd.Categorical(
clothes_df['size'],
ordered=True,
categories=['XS', 'S', 'M', 'L', 'XL']
)# size컬럼 기준으로 DataFrame을 다시 오름차순 정렬
clothes_df.sort_values(by='size')
# size기준으로 groupby 결과물도 오름차순 정렬됨
clothes_df.groupby('size').mean()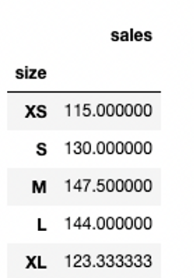
# 그래프 그리기
sns.barplot(data=clothes_df, x='size', y='sales')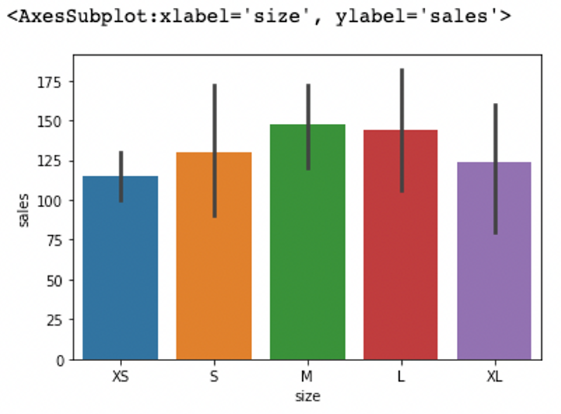
멀티 인덱스란?
여러개의 값을 인덱스로 가지고 있는 값을 '멀티 인덱스'라고 한다.
groupby를 할 때, 어떤 값을 먼저 넣어주느냐에 따라 멀티 인덱스의 형태가 달라진다.
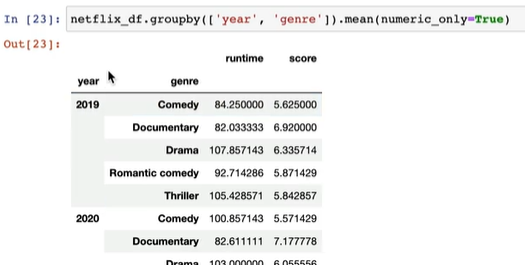
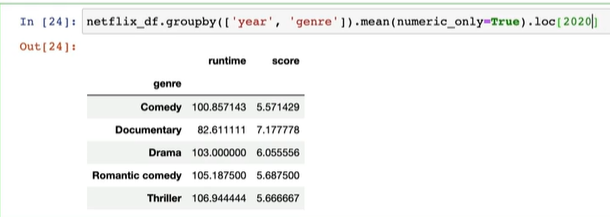
netflix_df.groupby(['year', 'genre']).mean(numeric_only=True).loc[2020, :]
# groupby(['year', 'genre'])는 'year'과 'genre' 열을 기준으로 데이터를 그룹화한다.
# .mean(numeric_only=True):그룹화된 각 그룹에 대해 평균을 계산하는데,
# numeric_only=True를 지정하여 숫자형 데이터만 포함되도록 한다.
# 즉, 문자열 등의 비숫자형 데이터는 평균 계산에 포함되지 않음
# .loc[2020, :]:평균이 계산된 결과에서 인덱스가 2020인 행을 선택한다.
# 이때, 가장 바깥쪽의 인덱스를 기준으로 값을 찾으므로, .loc에 바깥쪽의 인덱스를 기준으로 설정해주어야 함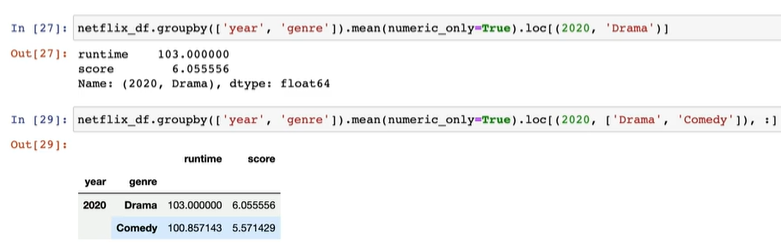
# 모든 연도의 정보를 year 변수에 정렬하여 저장
years = sorted(setflx_df['year'].unique())
# year과 Drama 장르를 기준으로 연도별 평균값 도출
netflx_df.groupby(['year', 'genre']).mean(numeric_only=True).loc[(years, 'Drama'), :]예제
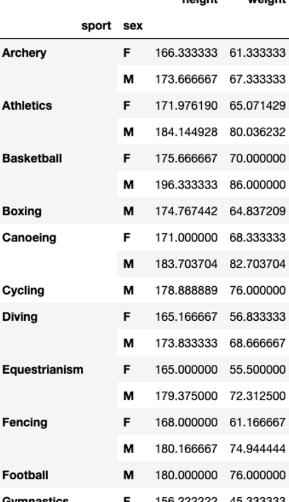
몬트리올 올림픽 메달리스트들의 키와 체중의 평균을 운동 종목별, 성별 기준으로 계산해 주세요.
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
olympic_df.groupby(['sport', 'sex'])[['height', 'weight']].mean()결과값
agg()
pandas의 DataFrame이나 Series에서 여러 가지 집계 함수(aggregation functions)를 동시에 적용할 수 있게 해주는 메서드이다. 주로 groupby와 함께 사용하여 그룹화된 데이터에 대해 다양한 통계치를 동시에 계산할 때 유용하다.
netflix_df.groupby('genre')['score'].agg(['mean', 'max', 'min'])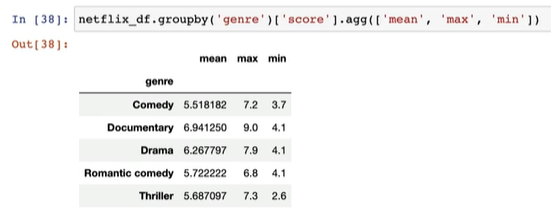
netflix_df.groupby('genre').agg({'score':'mean', 'runtime':['min','max']})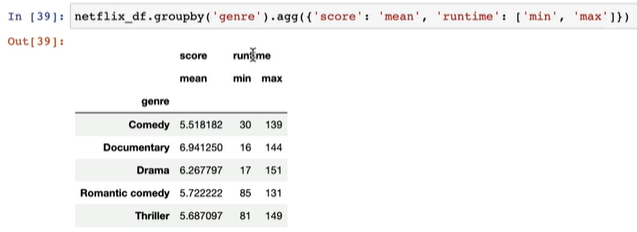
예제
몬트리올 올림픽 메달리스트들의 나이의 최솟값, 최댓값을 운동 종목별로 계산해 주세요.
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
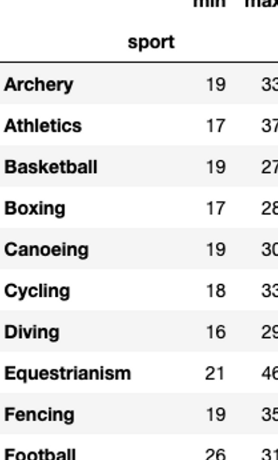
olympic_df.groupby('sport')['age'].agg(['min', 'max'])결과값
피벗 테이블
테이블을 요약해서 볼 수 있는 표를 의미한다.
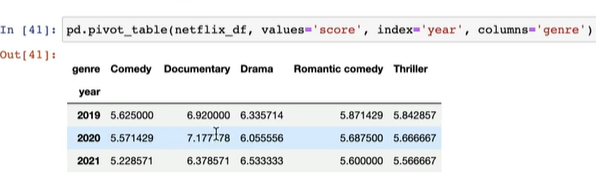
pd.pivot_table(netflix_df, values='score', index='year', columns='genre')
pd.pivot_table(netflix_df, values='score', index='year', columns='genre', aggfunc='max')
# values='score':피벗 테이블에서 집계할 값이 되는 열
# index='year':피벗 테이블의 행 인덱스
# columns='genre':피벗 테이블의 열 인덱스
# aggfunc='max': 집계 함수로, 그룹화된 데이터의 'score' 값에 대해 최대값을 계산함
# 즉, 각 (year, genre) 조합에 대해 'score' 열의 최대값을 찾는다.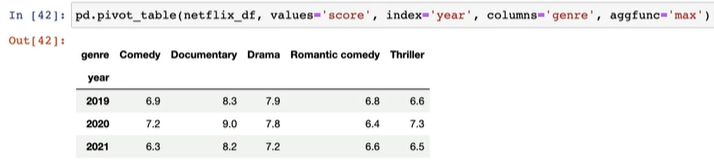
예제
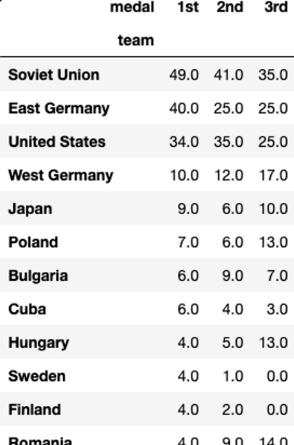
피벗 테이블로 몬트리올 올림픽의 국가별 금메달, 은메달, 동메달의 개수를 계산해 봅시다. 결측값은 0으로 채우고, 금메달 개수 기준으로 내림차순 정렬해 주세요. 정렬할 때, 은메달과 동메달 개수는 고려하지 말아 주세요! 참고로 메달 정보는 medal 컬럼에 저장되어 있고, 1st는 금메달, 2nd는 은메달, 3rd는 동메달을 의미합니다.
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
pd.pivot_table(olympic_df, index='team', columns='medal',
aggfunc='size').fillna(0).sort_values(by='1st', ascending=False)
결과값
resample()
# 일자를 기준으로 묶기
order_Df.resample('D').sum(numeric_only=True)
# 월을 기준으로 묶기
order_Df.resample('M').sum(numeric_only=True)
# 연도를 기준으로 묶기
order_Df.resample('Y').sum(numeric_only=True)